陶哲轩提前实测满血版o1:都能当研究生使唤了

还是现在大家都用不上的满血版本(眼泪不争气地从嘴角流出来)。
提前批大佬是怎么玩最新天花板的呢? 他向o1模型提出一个措辞模糊的数学问题,发现它竟然能成功识别出克莱姆定理。
而且答案是“完全令人满意的”那种。
当然,陶哲轩还做了一些其它测试,肉测下来总体体验就是: 比以前的模型更牛,多堆点提示
【千问解读】
好羡慕!原来早在8月份,陶哲轩就已经用上了OpenAI o1。
还是现在大家都用不上的满血版本(眼泪不争气地从嘴角流出来)。
提前批大佬是怎么玩最新天花板的呢?
他向o1模型提出一个措辞模糊的数学问题,发现它竟然能成功识别出克莱姆定理。
而且答案是“完全令人满意的”那种。

当然,陶哲轩还做了一些其它测试,肉测下来总体体验就是:
比以前的模型更牛,多堆点提示词表现还不错,但仍然会犯不小的错误,也没有产生啥自己的思想。
陶哲轩是这样形容的:
这种感觉,就像给一个平庸无奇但又有点小能力的研究生提供建议。
不过,这已经比以前的模型有所改进,因为以前的模型的能力更接近于实际上不称职的研究生。
但如果给以前的模型加点助力,比如计算机代数包和证明辅助工具啥的,改进一两次,就能实现进一步迭代,摇身一变,成为“有能力的研究生”。

陶哲轩对使用体验的这个神奇比喻在HackerNews等多个平台引起了激烈讨论。
有网友愤愤:GPT是什么**!我承认LLMs对写代码有很大帮助,但事实上有一些非常好的工具可以帮助解决这一问题,例如代码片段、模板和代码生成器。
有人就用陶哲轩的话回应了他:
“任何聪明到足以以编程为生的人,智商都足以成为一个平平无奇但又小有能力的数学研究生。
”

陶哲轩实测ChatGPT vs o1
陶哲轩展示了他自己的三轮测试。
第一轮,用去年3月份测试1316.ccChatGPT的题目,要求大模型回答一个措辞含糊的数学问题,只要从文献中找出一个合适的定理(克莱姆法则)就能解决。
Say I have a positive measure whose closure(support) = some compact convex subset S. I convolve n times to get a measure on nS. Scale down by n, take log, divide by n, take the limit to get some rounded thing on S. Does it depend on the original measure?
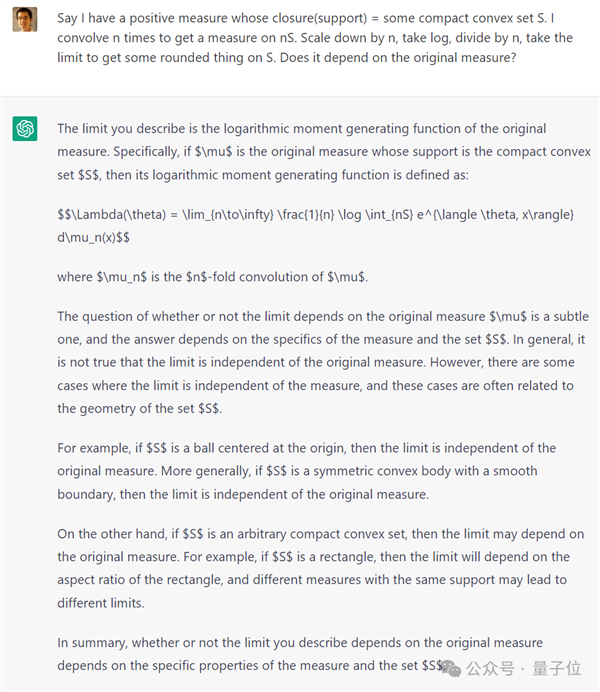
当时,ChatGPT倒是有模有样地回答了,期间还提到了一个高度相关的术语:对数矩生成函数,甚至在给出的答案中还讨论了一个具体的例子。
不过不能注意细节,全是幻觉,而且答案也是错的。
这一次,同样有模有样,但相较之下更有条理(更长还有大小标题区分度)。
最重要的是,o1成功找到了克莱姆定理,并给出了完全令人满意的答案。

ps,看记录,早在8月份陶哲轩就用上了o1。

第二轮,上一点难度,挑战复杂分析研究生课程的一个问题。
(之前他用来测试GPT-4的,要求他来协助编写一个证明)

结果这次陶哲轩的结论是,是要比之前GPT-4好些,但仍有点失望。
如果提供大量的提示和鼓励,新模型可以通过自己的努力得到一个正确的(而且写得很好的)解决方案,但它自己并没有产生关键的概念想法,而且确实犯了一些非同小可的错误。
光看到这几轮提示交互,确实是有点不满意的。
也难怪陶哲轩代入自己,把调教o1像是在教一个平庸、但又不是完全不称职的研究生。

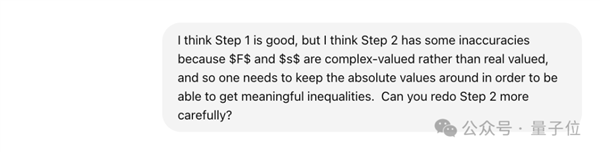

紧接着来第三轮测试,这一次是要求将质数定理的一种形式转化为Lean中的定理形式,方法是将其分解为若干个子问题分别描述,但不给出证明。

结果模型很好地理解了这个任务,并进行了合理的初步分解,不过代码中出现了几个小错误。
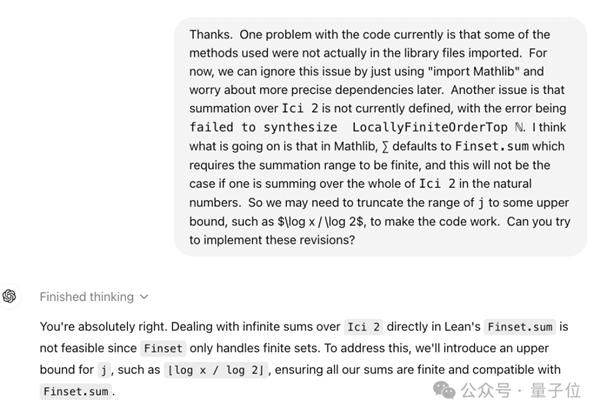
陶哲轩解释道,这是由于训练时缺乏有关Lean及其数学库的最新信息。
并表示,如果能专门针对Lean和Mathlib进行微调,并集成到一个IDE中,那应该会对公式化项目很有用。
在研究数学层面的实用性在增加
用大模型来搞研究,其实已经飞入寻常百姓家了。
一位账号名为wenc的网友分享了ta使用大模型来做研究的经历。
wenc从事着运筹学相关的工作,而OpenAI的模型们,从GPT 4o开始,就吸收了足够多的运筹学数据,能够输出很多非常有用的混合整数规划(MIP)公式。
举个栗子:
给4o一个逻辑问题,如“我需要根据分数将i个项目放入n个桶中,但我想按顺序填充每个桶”,4o会输出一个非常有用的数学公式。
通常情况下,只需要把公式微调一下就能完全搞定问题了。
此外,一些prompt太弱了的时候,4o还会预警:这可能导致输出不尽如人意——可以说对避免无效回答非常有用了。

回过头看咱还用不上大模型的时候,传统方法是需要大家在周末绞尽脑汁,试图找出有关MIP优化问题的无懈可击的公式。
对于非直观问题来说,这一点通常都令人头秃。
wenc很坚定地表示,每月从ChatGPT上获得的价值,远远超出了20美元(每月订阅费用)。
一旦GPT在Lean上得到更多调整——就像在 Python 上一样——我预计它在研究数学层面的实用性会有提升。
1316世界之最wenc还对那些抱怨Claude和GPT最新模型不好用的网友进行了分析:
不知道如何最大化自己的优势来使用大模型们;
把大模型想得无所不能,抱着“这玩意儿是解决一切的灵丹妙药”的期待;
大模型确实在他们的领域不适用。
wenc在最后弱弱补了一句,很多抱怨的人,其实都是属于前两种啦~~~

陶哲轩回应争议
尽管大多数网友都觉得大模型能帮助自己省下许多功夫,还是有人对陶哲轩“调教大模型如同调教不咋靠谱的研究生”的言论,充满了疑惑和不解。
有网友在陶哲轩的mathstodon底下留言:
亲,也许你可以展开说说“研究生”这块不?我理解一下子,你的意思是o1之前大模型放在Lean微调,再结合计算机代数包,那输出效果就可以媲美研究生水平?简单点来说,这种情况下的大模型能够解决一些新发现的重要课题?
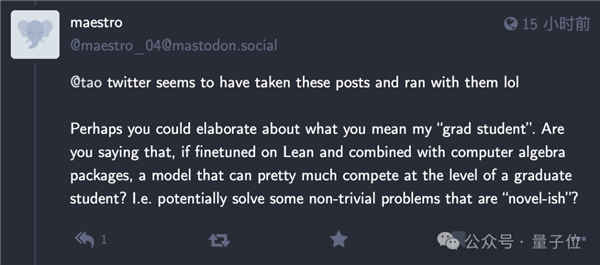
陶哲轩倒是很及时地回复了这条评论。
他表示,他正在考虑一个具体的指标,即“助手能够在专家数学家的指导下,协助完成复杂数学研究项目中的一个或多个具体任务”的程度。
一个有能力的研究生可以为这样的项目作出贡献,且这种贡献比“让学生加快项目进度并监督他们出了几成力”更有价值。
不过,即使使用最新的工具,让大模型输出正确且有用的回答,其实比输入精准prompt和验证结果都要难多了——当然,这之间的差距并不是特别巨大,前者大概要难个2-5倍的样子。
陶哲轩表示自己有理由相信,未来几年内,这个差距会降低到1倍以内(其实有些特定子任务,比如语义搜索、数据格式化或生成数字代码以协助数学研究探索,这个比率已经低于1了)。
他视“差距降到1倍以内”为数学领域将更广泛采用这些的转折点。

至于“研究生水平”嘛——
陶哲轩表示,自己这么说,只是为了方便大家感知啦!
虽然大模型可以协助研究人员完成当前的项目,但培养研究生的目的,是为了以后有更多的下一代独立研究者。
“我无意暗示研究生学习的各个方面,与数学中AI辅助的各个方面之间存在一一对应的1316世界之最关系。
”

One More Thing
最后,分享一则陶哲轩这个话题下,我们发现网友讨论出的、呼声挺高的一个结论——
虽然很难量化学会用大模型到底省了多少时间,但随着一个人提示词工程能力的提升,大伙儿能用更少的时间得到更好的效果。
但是!
显而易见,大模型的价值是因人而异的,它几乎取决于每个人的提示词水平。
呃,羞愧中……

不说了,过什么中秋节假期,咱这就去精进自己的prompt技巧去!
2024南京警察学院录取分数线各省汇总 提前批公安专业,2025参考
一、2024南京警察学院录取分数线南京警察学院作为一所公安类院校,在提前批和本科批都有录取,只是公安类专业只会在提前批录取,,因此本文就整理出公布本科提前批分数线,包含的江苏、湖南等地区南京警察学院的录取分数线,供大家查阅。
2024南京警察学院在全国各省最低录取分数线:1.北京:460分2.辽宁:历史类478分、物理类563分3.黑龙江:历史类509分、物理类469分4.江苏:历史类559分、物理类579分5.安徽:历史类522分、物理类478分6.江西:历史类572分、物理类448分7.湖北:历史类548分、物理类561分8.湖南:历史类556分、物理类582分9.广东:历史类532分、物理类541分10.广西:历史类531分、物理类485分11.海南:579分12.重庆:历史类500分、物理类557分13.四川:文科542分、理科560分15.贵州:历史类442分、物理类496分16.青海:文科505分、理科473分17.宁夏:文科441分,理科501分18.天津:526分2024南京警察学院各专业(组)在全国各省录取分数线:省份科类专业组性别最低分北京——01男607——02男460——03女589辽宁历史————478物理————563黑龙江历史001男521历史002女593历史003——509物理004男572物理005女608物理006男586物理007男490物理008女578物理009——469江苏历史01——560历史02——605历史03——559历史04——611物理05——623物理06——602物理07——624物理08——609物理09——583物理10——579物理11——612安徽历史001——584历史002——522物理001——605物理002——478物理003——605江西历史101——572历史102——590物理501——598物理502——615物理503——586物理504——448物理505——596物理561——448湖北历史01——605历史02——576历史03——557历史04——548物理05——618物理06——591物理07——587物理08——600物理09——573物理10——588物理11——561物理12——573湖南历史101男556历史102女608物理103男602物理104男582物理105女618广东历史101——532历史102——589物理103——576物理104——595物理105——541物理106——585广西历史801——536历史802——598历史803——547历史804——531物理805——547物理806——604物理807——546物理808——485物理809——573物理810——603物理811——554海南——01组男613——02组男579——01组女638——02组女642重庆历史——男518历史——男500历史——女556物理——男587物理——男585物理——女616物理——男557四川理科——男560理科——女603文科——男542文科——女582贵州物理501男594物理502男591物理503女611物理504男573物理505男594物理506男496物理507女596物理508男537物理508男600历史101女601历史102男442历史102男499历史103男495青海文科——男505文科——女538理科——男473理科——女549宁夏文科————441理科————501天津——01组——526——02组——575二、南京警察学院2024招生计划2024南京警察学院面向全国31个省(自治区、直辖市)招生1795名,招生专业全部为公安类专业,招生计划最多的三个地区是黑龙江(324人)、江苏(250人)、广东(150人)。
南京警察学院2024年分省、分就业面向、分专业招生计划数汇总如下:三、南京警察学院实力简介南京警察学院是一所隶属于公安部的本科公立高校,在人才培养方面,南京警察学院设有多个公安本科专业,并拥有国家一流本科专业建设点和江苏省卓越工程师培养计划专业。
其教职工队伍实力强大,包括众多高级职称和具有博士学位的专任教师。
毕业生就业方向广泛,主要集中在公安机关、司法机关及其他相关领域。
南京警察学院的毕业生就业质量较高,入警率也相对较高。
在院校合作方面,南京警察学院积极与公安机关和其他相关机构开展交流合作,推动公安工作和队伍建设高质量发展。
例如,该校与博州公安局签署了交流合作框架协议,旨在加强双方之间的紧密联系与深度合作。
想要报考该校的同学,可以在本文末尾输入分数,查看该校近三年的录取情况,了解自己能上该校的哪些专业。
北京警校录取分数线2024男女生汇总:含提前批最低分
其中男生最低分为460分(南京警察学院),女生最低分为558分(中央司法警官学院)。
本文收集汇总了北京2024年提前批招生警校录取分数详情,以供2025届考生参考。
需要注意的是,本文中提到的新疆警察学院公布的分数为公安机关加试及公务员录用考试成绩,总分与高考分数有异,仅供参考。
一、2024年北京警校男生录取分数线根据北京教育考试院发布的2024本科提前批分数文件显示,警校男生录取分数范围在460分~607分之间(不含新疆警察学院)。
其中最低分和最高分专业组均来自于南京警察学院,最低分专业组要求必选物理+化学,最高分专业组要求必选政治。
2024年想要报考警校的北京考生(男)分数至少要在本科线上26分左右,当然因为每年的录取竞争力度不同,具体还是要以当年实际情况为准。
下面是各院校招男生的具体分数情况:(1)北京警察学院必选政治:最低分525分;必选物理+化学:最低分522分;(2)南京警察学院必选政治:最低分607分;必选物理+化学:最低分460分;(3)郑州警察学院必选政治:最低分513分;必选物理+化学:最低分531分;篇幅有限,各校完整录取最低分数可见下表(在本文上下方输入分数,可查能上的大学名单):二、2024年北京警校女生录取分数线根据北京教育考试院发布的2024本科提前批最低分数文件显示,警校女生录取分数范围在558分~637分之间(不含新疆警察学院)。
其中最低分专业组来自中央司法警官学院(558分),要求必选政治;最高分专业组来自中国人民公安大学(637分),要求必选政治。
2024年想要报考警校的北京考生(女)分数至少要在本科线上124分左右,当然因为每年的录取竞争力度不同,具体还是要以当年实际情况为准。
下面是各院校招女生的具体分数情况:(1)北京警察学院必选政治:最低分607分;必选物理+化学:最低分586分;(2)南京警察学院必选物理+化学:最低分586分;(3)郑州警察学院必选政治:最低分587分;必选物理+化学:最低分579分;篇幅有限,各校完整录取最低分数可见下表(在本文上下方输入分数,可查能上的大学名单):












