
为机器人安上“最强大脑”!谷歌VLA新模型泛化能力提升3倍 能“听懂人话”
【千问解读】
《科创板日报》7月31日讯(编辑 郑远方)一个单臂机器人“站”在桌前,桌上放着三个塑料动物玩具:狮子、鲸鱼与恐龙。
收到“捡起灭绝的动物”指令后,这个机器人“思考”了一会儿,然后甚至机械臂,打开爪子,抓起了恐龙。
这是谷歌最新一款机器人模型Robotic Transformer 2(机器人变形金刚2,RT-2)。
上文这个“抓起恐龙”的动作对于人类而言轻而易举,对于机器人而言却堪称一个重要飞跃——之前机器人经常无法操纵自己从未见过的东西,也难以实现从“灭绝的动物”到“塑料恐龙”的逻辑飞跃。
作为一款新型视觉-语言-动作(vision-language-action,VLA)模型,RT-2可以从网络、机器人数据中学习,并将这些知识转化为机器人控制的通用指令。
相较于其他机器人研究,RT-2的核心优势在于,其不仅能直接接收“人话”指令,听懂“人话”、理解“人话”,还能做出相应推理,并转为机器人能理解的分阶段指令,从而做出动作完成任务。
RT-2完成的每一项任务,都要求其理解视觉语义概念、并通过控制机器人实现操作这些概念。
例如接到“捡起桌子上快掉下去的袋子”、“将香蕉移动到2加1的总和处”这种指令时,机器人需要对相应物体/场景执行任务,而这些物体与场景它从未在机器人数据中见过,需要从网络数据中转化得到相应知识。


总体而言,RT-2具备三大能力:符号理解(Symbol understanding)、推理(Reasoning)和人类识别(Human recognition)。
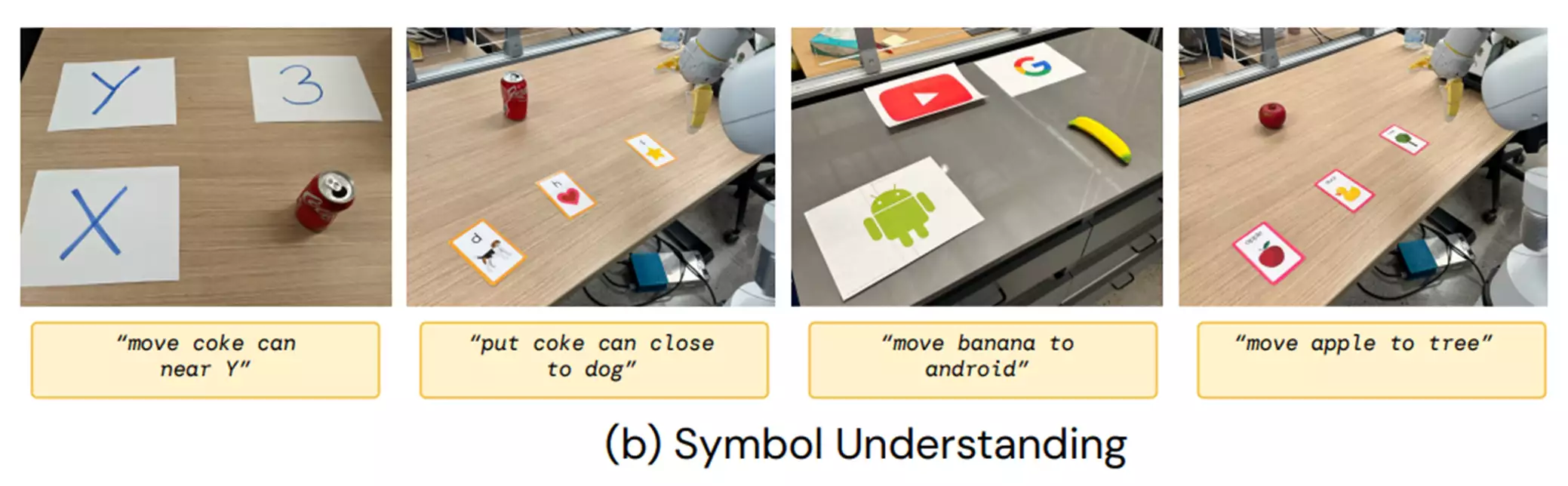
(1)符号理解是指RT-2可以从视觉语言预训练中转移了语义知识,而这些语义知识在机器人数据中并不存在。
这类指令示例包括“将苹果移到3号位置”或“将可乐罐推到心形上”。
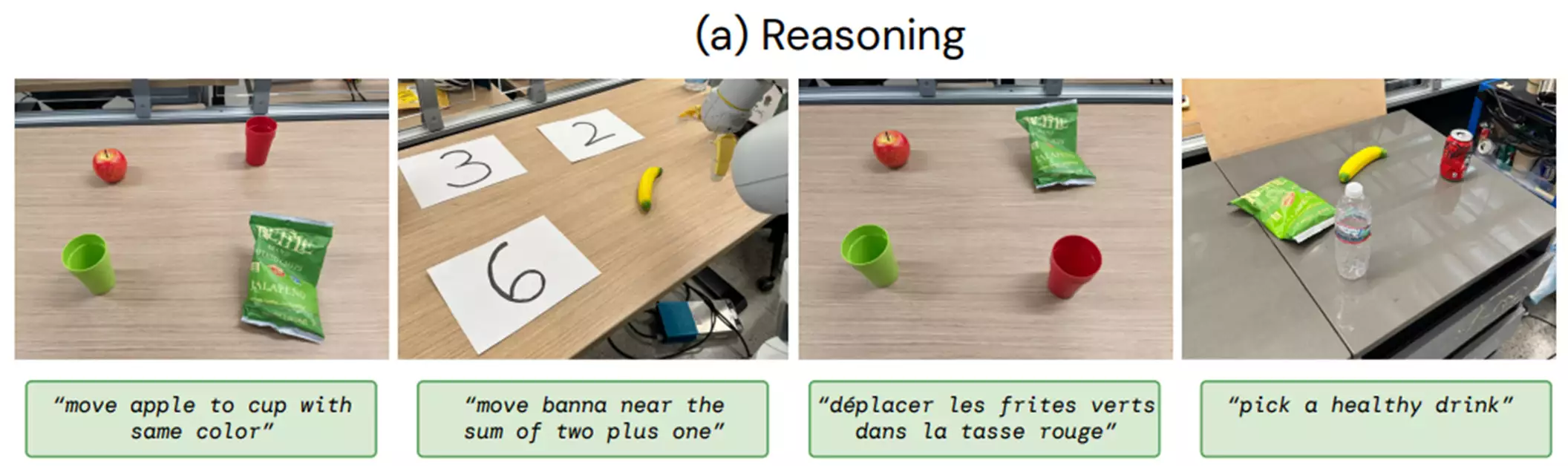
(2)推理则是将VLM的各种推理能力用于任务控制,包括视觉推理(“将苹果移到相同颜色的杯子里”)、数学推理(“将X移到2加1之和的附近”)、多语言理解(“mueve la manzana al vaso verde”,西班牙语)。
(3)人类识别是以人类为中心的理解和识别能力,RT-2可以完成“将可乐罐移到戴眼镜的人身边”这类任务。

此外,研究人员还将机器人控制与思维链推理相结合。
首先用自然语言描述机器人即将采取的动作的目的,然后是“动作”和动作标记。
例如在下图中,RT-2接收到的要求是“我想钉个钉子,场景里什么东西可能能用上?”,RT-2转化得出了“石头。
动作:1 129 138 122 132 132 106 127”的指令,并拿起了石头。

RT-2还能更好地适用于不同的、机器此前没见过的场景。
比起在大型数据集上预训练的RT-1、Visual Cortex(VC-1)等模型,RT-2泛化能力大幅提高,较前者提高了3倍有余。
加利福尼亚大学伯克利分校的机器人学教授Ken Goldberg表示,机器人的灵巧性仍达不到人类水平,在一些基本任务上也会失败,但谷歌利用人工智能语言模型,赋予机器人推理和随机应变的新技能,是一个很有希望的突破。
解析:为什么说楚霸王项羽鸿门宴上不杀汉高祖刘邦比范增高明
”一首霸王别姬,唱得山河为之动摇,世人不禁为霸王的凄凉结局而悲恸。
很多人更是认为,霸王边的结局是他在上的心慈手软造成的。
如若当初鸿门宴上,霸王采纳亚父的建议,于宴上取下首级,也许历史将会改写。
其实不然,霸王项羽并非只是有勇无谋的莽夫。
若那时他草率取了刘邦首级,也许不等乌江自刎,他也要早早了。
所以说纵使最后是刘邦逼得项羽自刎乌江,而项羽鸿门宴上没取其性命仍是明智之举。
其实仔细研读《》就会发现,笔者上面提出的言论并非无稽之谈。
为解其中之隐秘,接下来笔者将从鸿门宴前后的史实着手,来鸿门宴上项羽为何不杀刘邦。
死后,秦帝国暴虐苛政,民不聊生,老百姓群起而反之,各路英雄皆起兵,欲取秦而代之。
、项羽叔侄起兵,推楚王孙为怀王,恢复楚地,时刘邦率众来投。
因此时的秦军主力,一在南越拓土,一在长城守边,故六国诸侯军得以借此机会整顿复兴。
但不久,秦少府率军平乱,先后打败并斩杀了、、项梁等人,又邀击诸侯于赵国,战局迅速变得对秦有利。
在形势危急之际,怀王召集宋义、项羽、刘邦议事,决定兵分两路,一路北上,消灭秦军主力,并慑服诸侯,再一同取道函谷关人关中;一路西进,经武关进入关中,取咸阳灭秦。
怀王与宋义、刘邦约定,谁先人关中,就可以在关中称王。
也正是这个约定,成了后来鸿门宴的诱因。
网络配图 现在先来说说这两路联军。
西路主将是刘邦,北路主将则是宋义。
刘邦率领的西进军,一路智取力夺,居然先项羽打进关中。
其实并非刘邦运气好,而是其本身就具有非凡的军事才能。
刘邦是后来投奔楚军的,他的人马并非楚军主力,他手下的这支兵也大多是一些跟着他从沛县造反出来图口饭吃的老乡亲。
他一边打仗,一边收聚陈胜、项梁战败后的散兵游勇,也收编了几个大城市投降的守军。
纵使这样,刘邦打到咸阳时也才只有十万余人而已。
如此,刘邦卓越的军事才能就充分体现出来了。
刘邦深知民心的重要性,于是兴仁者之兵;他明白战场变幻莫测,于是熟谙诡谋之用。
如此看来,刘邦能先项羽入主咸阳,靠的就不光是运气了。
而且刘邦入主咸阳后,对手下将士约法三章:妥善安置故吏,不抢秦宫女人,不杀降顺将士,不贪府库财宝。
当一切安排妥当之后,刘邦更是做出了惊人之举——老老实实退军霸上。
这又是刘邦高人一处的地方。
其实一个人若想成功,他必先有的品质就是白知之明!刘邦清楚现在自己还不是项羽的对手,那么他只有把自己包装成一个道德完美的圣人,一位亲切的战友,一位身先士卒的前锋。
正是自己的这份低调,让项羽在鸿门宴上找不到杀自己的理由。
由此可见,刘邦的确非等闲之人。
说到刘邦的机智就不得不提一人,那就是。
《史记·鸿门宴》中记载,范增曾对项羽说:“沛公居山东时,贪于财货,好美姬……” 既然刘邦本性好色,那他刚人咸阳时,见秦宫美色怎能不动心?而这时,正是樊哙当头棒喝,将其骂醒后拽到霸上,后来樊哙更是在鸿门宴上闯营救主。
大智大勇,樊哙还真不是有勇无谋的莽夫呢! 刘邦克制住自己的欲望,驻军霸上,就等项羽前来,双手奉上自己打下的咸阳。
那么这时项羽一支北上的军队战况又是如何呢? 前文笔者也提到,北路军的主帅是宋义。
此人在进军途中打起了小算盘,北路军走到半路,宋主将突然勒令军队止步不前,隐隐有坐观天下成败,拥军自立的意思。
这下项羽可不干了,他还等着杀人咸阳,挣个王做做呢。
于是,项羽、范增合谋,送宋老儿去了西天,抢夺了军权。
然后,渡河与秦军展开了历史上有名的,一举歼灭秦军,并且一战成名,令各路诸侯畏惧不已。
战胜秦军之后,项羽率军雄赳赳气昂昂地向关中挺进。
可在行军途中,项羽犯了一个致命的错误,就是鲁莽之中坑杀秦降军将士二十万之众。
和刘邦礼贤下士,礼待降兵相比,无疑又落后很多。
一路凯歌唱到函谷关,联军却发现刘邦早已先人关中了,并派兵守备了函谷关。
项羽杀主帅,歼秦军,一路披荆斩棘打到关中,却眼睁睁看着刘邦抢了头彩,他是无论如何不会甘心的,于是一怒之下就破关而人了。
项羽拥兵四十万,驻扎在了新丰鸿门。
安顿下来的项羽开始思考接下来的战略部署。
要把关中王拱手让给刘邦,项羽自是十二分不情愿。
但分析当前形势之后,项羽才发现,形势对于他而言,非常不乐观。
此时,项羽虽号称拥兵四十万,但其中大多数都是诸侯的部队——这些人中有些是心存观望,并没有真正归附,有些甚至被解除了武装。
其实此时项羽真正的本部只有十几万人而已。
与此同时,刘邦的军队亦有十万,驻扎在霸上。
项羽清楚,若此时自己与刘邦火并,诸侯军队肯定乐于坐山观虎斗,并不会有几人能真正帮助自己。
所以,就算项羽能胜,也将元气大伤。
网络配图 而且即使项羽能杀掉刘邦,其部队也不可能轻易就会被他兼并(刘邦军中有不少秦人,而项羽刚刚坑杀了二十万秦人)。
并且项羽此前杀宋义,有范增与全军将土的支持;坑秦兵,有诸侯军队相助。
而现在项、刘之间的矛盾还没有公开化,他们都还是怀王手下的将军,都是楚军,若此时项羽要杀刘邦,那些诸侯会帮助他吗?答案是否定的。
可这时出现一个来告密的叛徒,此人正是刘邦左司马。
曹无伤派人告密说刘邦在关中称王,封为宰相,独享所有奇珍异宝。
曹无伤这么一说可谓是火上浇油,再加上范增一顿故弄玄虚的教唆,项羽盛怒之下就要攻打刘邦。
若照此发展下去,刘邦是必死无疑了。
可贵人总是福大命大的。
救刘邦一命的乃是项羽亲族——。
此人颇有智慧,他似乎预见了项羽早晚灭亡,但又碍于亲族身份不能反叛项羽,所以,项伯身在楚营却心在刘邦,暗地帮助刘邦。
史料记载,后来刘邦家眷被项羽扣为人质,也亏他从中维护。
刘邦称帝之后,被杀殆尽(虽然官方说法是“皆不诛”),但他这一支却安然无恙,而且被赐姓“刘”。
这些当然都是后话了。
其实冷静下来的项羽也明白,刘邦现在是杀不得的。
目前最重要的不是杀掉刘邦,而是赶紧乘此时机,利用自己的威势一鼓作气铲除对手,聚拢人心,创立霸业。
所以,当项伯回营向项羽禀报说,刘邦并未染指秦宫室、,并日夜期盼项羽前来接管时,他也就为自己找好台阶下了。
深思熟虑后,在鸿门宴前夕,项羽就已放弃了第二天修理刘邦的打算了。
可见,项羽没杀刘邦非但不是妇人之仁,反而恰恰是十分明智之举。
这次与刘邦握手言和,为他日后成为打下了基础。
可接下来,项羽却地犯了一些致命的错误。
其中,最大的一个错误就是后来没有除掉刘邦。
项羽称霸后,能与其争雄的只有两个人了,一个是刘邦,一个是田荣。
本来刘邦已是项羽刀俎下的鱼肉了,项羽可以找到—一万个借口将其除之,以绝后患——就像刘邦后来杀、那样。
至此,霸王又有一点不如刘邦了,那就是如何让对手在适当的时间适当地消失。
当然,也有范增这样“智者’’的误导因素在其中。
可霸王却偏偏封刘邦在汉中,天高远,,霸王再想杀刘邦就没那么容易了。
后来,项羽同激战时,刘邦乘虚而人,杀进中原。
网络配图 此外,项羽还犯了两个致命错误:一是破咸阳后,他独占秦宝,并挟之东归彭城。
这也成为日后众诸侯偷袭彭城的一个诱因,刘邦答应他们,破城之后,平分其宝。
二是称霸后乱封诸侯,项羽主持分封如同儿戏,各国旧王族被挤走,甚至没有了领地,而分封在最好地方的则是项羽的战友和亲信。
这成为其后几年大起战端的直接原因。
如此看来,项羽在驭人之术上远不如刘邦。
至此,鸿门宴上项羽不杀刘邦的原因也就明了了。
其实,若把争夺江山比做一场考试的话,项羽就好比一个有些怪才的考生,潇洒地做出了旁人都做不出的高难度附加题——如鸿门宴上放走刘邦,却在正式题中交了白卷,以致考砸。
项羽一生犯了很多错误,这些才是导致他最终四面楚歌,自刎乌江的真正原因,而非是在鸿门宴上放走刘邦。
若是一定要在霸王项羽争夺江山的政治决策中找出些闪亮之处的话,那可能就要当数鸿门宴上没杀刘邦了,不然的话,有没有后来的霸王都很难说呢。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。
为什么风流皇帝乾隆后妃比康熙少却被评为风流帝王呢?
他终年八十九岁,年寿之高是任何皇帝都无法比拟的。
再说他执政六十年,把皇位让给了皇十五子,改年号为,那是出于无可奈何,因为登基时就宣称:他的祖父皇帝对他万分器重,为表示他要报答祖父的恩德,自己在位年数一定不能超过祖父在位的年数。
已创出了中国历史上皇帝掌权六十一年的最高纪录,所以乾隆皇帝执政六十年时,虽然身体还很健康,精力还十分旺盛,但他要信守自己的诺言,所以不得不让位。
可是当他荣升为太上皇时,他依然对政权情有独钟,牢牢地掌握着实际权力。
大廷对外使用“嘉庆”年号,而在宫内档案中,依旧沿用“乾隆”年号,一直到乾隆皇帝死时,已到了乾隆六十四年(1799年)。
实际乾隆皇帝掌实权达六十三年零四个月之久,依实情而论,乾隆皇帝才是中国历史上执政时间最长的皇帝。
网络配图 通常人们都称颂康熙大帝的功业,岂不知康熙皇帝是八岁登基,再聪慧完美的神童,也挑不起清朝初期繁复的治国大业,康熙早期的执政,是靠祖母文皇后和群臣的辅佐,才为后来大清帝国开创了大好的局面;而乾隆二十五岁登基,又承继了康熙、两朝的基业,凭着他自身的聪明才智和实干能力,足以达成安邦治国平天下的伟业。
乾隆皇帝才是中国历史上一位创建非凡大业的皇帝。
乾隆皇帝的后宫生活远不如他的祖父。
康熙皇帝一生拥有五十五位后妃,五十五个子女,是清朝十位皇帝中后妃最多、子女最多的人。
奇怪的是,很少有人评论康熙皇帝贪恋女色,也很少有人议论康熙皇帝治家教子无方;而乾隆皇帝一生有四十一位后妃,却常常被后人评为“风流皇帝”。
他与后妃的故事,远不如他的曾祖父皇帝那么浪漫。
但主要因为乾隆皇帝是很感情用事的,他与那些后妃生离死别的故事,着实感人,也留下了一些遗恨。
网络配图 乾隆皇帝身为皇子时,称四阿哥。
雍正五年,四阿哥才十七岁,由其父做主,娶了察哈尔总管李荣保之女为福晋(妻子),后来又娶了两个侧福晋(妾),还有些名分低些的女子,身边共有妻妾七八位。
另外还有十名女子侍奉。
这十名女子中,除了年长些称做“妈妈里”的女用人外,还有六名“官女子”。
这些“官女子”是从内务府包衣的女儿中挑选出来的,自不必说,她们个个长得,都是十分惹人喜爱的妙龄女子。
雍正九年,二十一岁的四阿哥有两名妻妾分娩,此时他又与一名侍奉他的“官女子”发生了关系。
在《宫内等处添减女子嬷嬷妈妈里底账》中记载:雍正九年四月二十日总管王朝卿等差司房卢玉堂传说,“四阿哥下官女子一人遇喜,每日外添肉一斤,姥姥一人每日外添肉一斤”。
四阿哥下的官女子遇喜,作俑者只能是四阿哥。
可是,四阿哥与这位官女子所怀的孩子却不见出生的记载。
查雍正九年,只有庶妃富察氏(后来封为哲悯皇贵妃)于四月二十七日寅时生下四阿哥的第二女,至十二月初九日申时就夭亡了。
到五月二十七日福晋富察氏(后来封为孝贤皇后)生下四阿哥的第三女。
除此以外,自雍正九年至十年,四阿哥均无子女出生的记载。
“雍正十年七月三十日总管陈福传说,四阿哥下官女子一人病故。
”也许病故的官女子就是雍正九年四月遇喜的那位女子。
四阿哥在“雍正十一年癸丑春正月封为和硕宝亲王”。
到了“雍正十一年十二月初五日,苏培盛等差司房太监张福寿传说,宝亲王下官女子一人遇喜,添守月姥姥二人”。
有了守月姥姥二人,即是官女子快要临盆了,可是宫中却不见有四阿哥宝亲王的子女出生。
遍查宝亲王的众多妻妾中,雍正十一年并没有出生过子女,一直到雍正十三年才有第三子出世。
按说宫中后妃地位较高者,尽管所生下的孩子只活了很短的时日,也会有某阿哥、某皇女殇逝的记载。
而雍正九年和雍正十一年,有两位四阿哥下官女子遇喜,却没有生儿生女的一丝记载。
这不外乎是因为官女子出身低微,怕丢了四阿哥宝亲王的面子,故而没留下任何记载。
至于遇喜的官女子命运如何?尚无从查考。
在四阿哥的六位官女子中就有两位怀有身孕,可见四阿哥是一个道地的“情种”。
网络配图 许多皇帝在掌权的时候,会用他手中的权力去修改历史,凡是对他不利的、不光彩的史料记载,总是要从史册中删除的。
可是不管哪朝哪代,都不可能把所有的宫中生活杂记档案都一一地清查,也不可能删除得干干净净。
偏偏在人们都不注意的生活杂记档案《宫内等处添减女子嬷嬷妈妈里底账》中,露出了乾隆皇帝身为皇子时一段鲜为人知的生活隐私。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。
声明:本文内容仅代表作者个人观点,与本站立场无关。
如有内容侵犯您的合法权益,请及时与我们联系,我们将第一时间安排处理

















